Support me on Patreon to write more tutorials like this!

There are lots of tutorials about how to use Celery with Django or Flask in Docker. Most of them are good tutorials for beginners, but here , I don’t want to talk more about Django, just explain how to simply run Celery with RabbitMQ with Docker, and generate worker clusters with just ONE command.
Of course , you could make an efficient crawler clusters with it !
1. Concept Map of producer and consumer
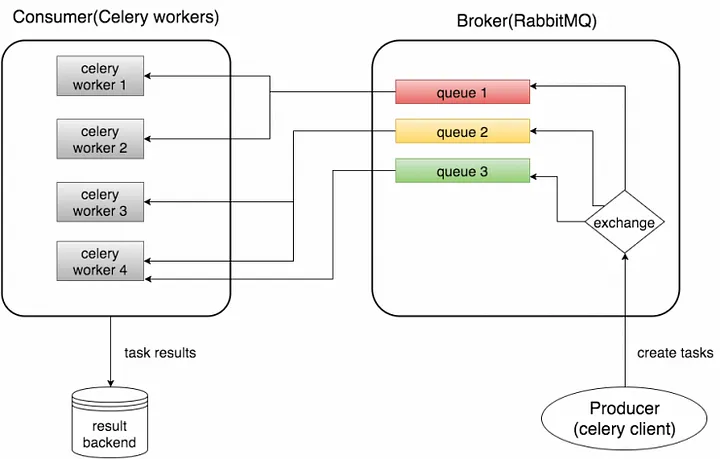
Source: test4geeks.com
Celery is an asynchronous task queue/job queue based on distributed message passing. It is focused on real-time operation, but supports scheduling as well.
The execution units, called tasks, are executed concurrently on a single or more worker servers using multiprocessing, Eventlet, or gevent. Tasks can execute asynchronously (in the background) or synchronously (wait until ready).
As mentioned above in official website, Celery is a distributed task queue, with it you could handle millions or even billions of tasks in a short time.
Celery requires a messaging agent in order to handle requests from an external source, usually this comes in the form of a separate service called a message broker.
There are many options for brokers available to choose from, including relational databases, NoSQL databases, key-value stores, and messaging systems. Here , we choose RabbitMQ for messaging system. RabbitMQ is feature-complete, stable, durable and easy to install. It’s an excellent choice for a production environment.
2. Install Docker and Docker-compose
Check the tutorial to install Docker
sudo apt-get update
sudo apt-key adv — keyserver hkp://p80.pool.sks-keyservers.net:80 — recv-keys 58118E89F3A912897C070ADBF76221572C52609D
sudo apt-add-repository ‘deb https://apt.dockerproject.org/repo ubuntu-xenial main’
Install docker-compose as below or check the tutorial of Docker official website.
sudo apt-get install docker-compose3.Structure of the code
The structure of code shows below
docker-cluster-with-celery-and-rabbitmq
-- test_celery
-- __init__.py
-- celery.py
-- tasks.py
-- run_tasks.py
-- docker-compose.yml
-- dockerfile
-- requirements.txtNext I will explain the code in details step by step:
celery.py
from __future__ import absolute_import
from celery import Celery
app = Celery('test_celery',broker='amqp://admin:[email protected]:5672',backend='rpc://',include=['test_celery.tasks'])The first argument to Celery is the name of the project package, which is “test_celery”.
The second argument is the broker keyword argument, which should be specified the broker URL. Here using RabbitMQ.
Notice: admin:[email protected]:5672, you should change it to what you set up for your RabbitMQ. user:password@ip:port
The third argument is backend, which should be specified a backend URL. A backend in Celery is used for storing the task results. So if you need to access the results of your task when it is finished, you should set a backend for Celery. rpc means sending the results back as AMQP messages. More options for messages formats can be found here.
tasks.py
from __future__ import absolute_import
from test_celery.celery import app
import time,requests
from pymongo import MongoClient
client = MongoClient('10.1.1.234', 27018) # change the ip and port to your mongo database's
db = client.mongodb_test
collection = db.celery_test
post = db.test
@app.task(bind=True,default_retry_delay=10) # set a retry delay, 10 equal to 10s
def longtime_add(self,i):
print 'long time task begins'
try:
r = requests.get(i)
post.insert({'status':r.status_code,"creat_time":time.time()}) # store status code and current time to mongodb
print 'long time task finished'
except Exception as exc:
raise self.retry(exc=exc)
return r.status_code
In this file , you can see that we import the app defined in the previous celery module and use it as a decorator for our task method. Note that app.task is just a decorator. In addition, we sleep 5 seconds in our longtime_add task to simulate a time-expensive task.
run_tasks.py
from .tasks import longtime_add
import time
if __name__ == '__main__':
url = ['http://example1.com' , 'http://example2.com' , 'http://example3.com' , 'http://example4.com' , 'http://example5.com' , 'http://example6.com' , 'http://example7.com' , 'http://example8.com'] # change them to your ur list.
for i in url:
result = longtime_add.delay(i)
print 'Task result:',result.resultHere, we call the task longtime_add using the delay method, which is needed if we want to process the task asynchronously. In addition, we keep the results of the task and print some information. The ready method will return True if the task has been finished, otherwise False. The result attribute is the result of the task (“3” in our ase). If the task has not been finished, it returns None.
docker-compose.yml
The main code of consumer and producer has been finished, next we will setup docker-compose and docker.
version: '2'
services:
rabbit:
hostname: rabbit
image: rabbitmq:latest
environment:
- RABBITMQ_DEFAULT_USER=admin
- RABBITMQ_DEFAULT_PASS=mypass
ports:
- "5673:5672"
worker:
build:
context: .
dockerfile: dockerfile
volumes:
- .:/app
links:
- rabbit
depends_on:
- rabbit
database:
hostname: mongo
image: mongo:latest
ports:
- "27018:27017"In this file, we set the version of docker-compose file to ‘2", and set up two “services”: rabbit and worker. What we should noticed here is ‘image’, we will pull “rabbitmq: latest” image later with docker.
Here we need to build a docker image with celery for worker. And run when it start with ENTRYPOINT
FROM python:2.7
ADD requirements.txt /app/requirements.txt
ADD ./test_celery/ /app/
WORKDIR /app/
RUN pip install -r requirements.txt
ENTRYPOINT celery -A test_celery worker --concurrency=20 --loglevel=infocelery==4.0.2
requests
pymongo==3.4.0Lots of code? Just download all of them from Github
Before the next step start, we should pull down the rabbitmq image and build worker image.
docker pull rabbitmq:latest
cd /directory-of-dockerfile/
docker-compose buildOnce it’s done, you will see ‘celeryrabbitmq_worker’ and ‘rabbitmq’ when you type cmd ‘docker ps -a’ in the terminal.
Fire it up!
Now we can start the workers using the command below(run in the folder of our project Celery_RabbitMQ_Docker)
docker-compose scale worker=5Then you will see the terminal shows below, when the ‘done’ shows up , that means all the 5 workers has been created and started well.
Creating and starting celeryrabbitmq_worker_2 … done
Creating and starting celeryrabbitmq_worker_3 … done
Creating and starting celeryrabbitmq_worker_4 … done
Creating and starting celeryrabbitmq_worker_5 … doneNext type in the command:
docker-compose upThen you will see something like below:
(Updated, thanks for jlkinsel’s comment. If you have “docker-compose up” run before and then stoped , docker-compose up again , it will shows “Starting celeryrabbitmq_rabbit_1” . Both works here)
celeryrabbitmq_rabbit_1 is up-to-date
celeryrabbitmq_worker_2 is up-to-date
celeryrabbitmq_worker_3 is up-to-date
celeryrabbitmq_worker_4 is up-to-date
celeryrabbitmq_worker_5 is up-to-date
Attaching to celeryrabbitmq_rabbit_1, celeryrabbitmq_worker_5, celeryrabbitmq_worker_2, celeryrabbitmq_worker_4, celeryrabbitmq_worker_3, celeryrabbitmq_worker_1
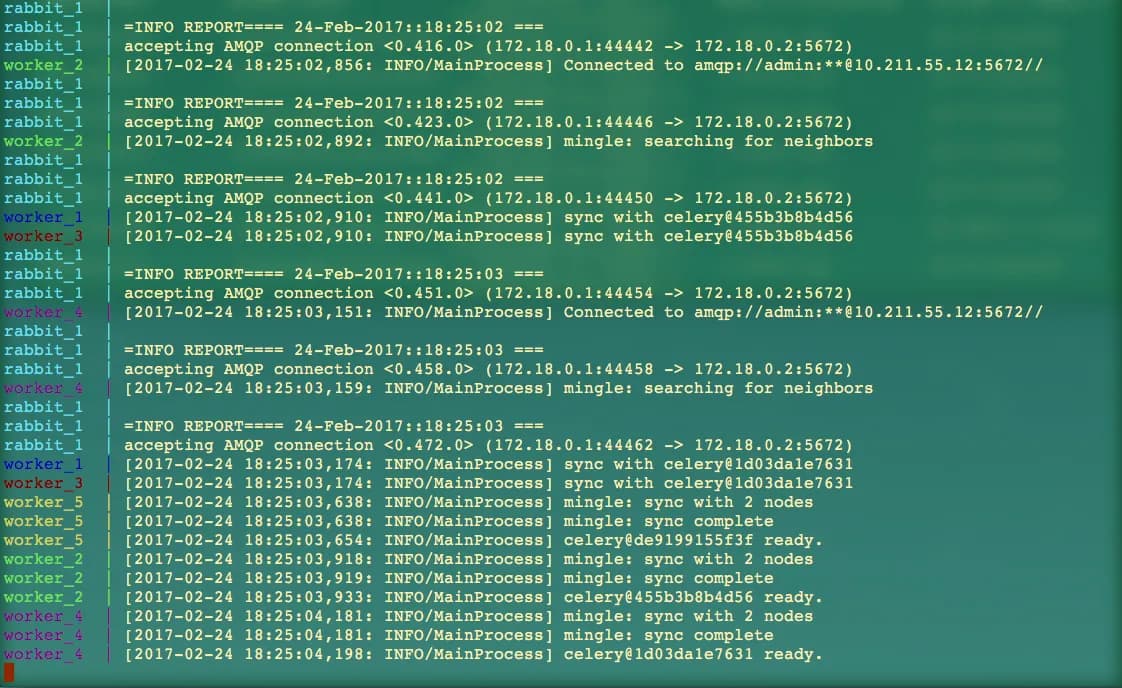
By now , all the five workes has been started , and ready to receive messages. If there is any messages from produce you will see the results here.
OK, open another terminal and go to the project directory, docker-cluster-with-celery-and-rabbitmq. Let’s start the producer:
docker exec -i -t scaleable-crawler-with-docker-cluster_worker_1 /bin/bash python -m test_celery.run_tasks*Thanks for fizerkhan‘s correction.
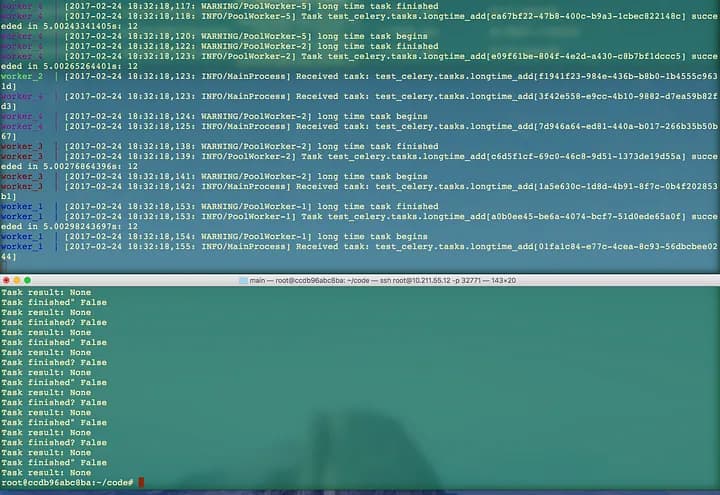
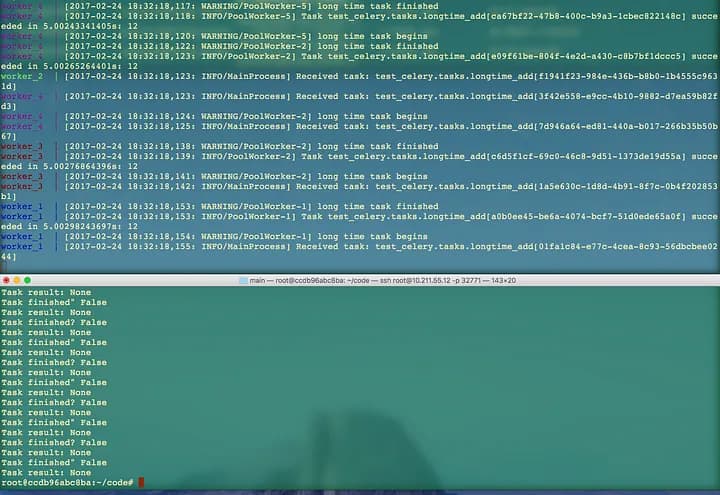
Now you can see the results from this screenshot. The number 12 behind “Task test_celery.tasks.longtime_add” is the result calculated by “tasks.py”.
Here I just change “result = longtime_add.delay(1,2)” to (10,2), then the result is 12, you can change it to any you want to test it if runs well.
Conclusion
It’s just simple demo to show how to build a docker cluster with Celery and RabbitMQ in a short time. It will help you have a good understanding of Docker , Celery and RabbitMQ. With a powerful single machine or cloud cluster , you will handle large tasks easily. If you just have a single machine with low specifics , multiprocessing or multithreading perhaps is a better choice.