Support me on Patreon to write more tutorials like this!

Introduction
In this tutorial, we will walk you through the process of building a distributed crawler that can efficiently scrape millions of top TikTok profiles. Before we embark on this tutorial, it is crucial to have a solid grasp of fundamental concepts like web scraping, the Golang programming language, Docker, and Kubernetes (k8s). Additionally, being familiar with essential libraries such as Golang Colly for efficient web scraping and Golang Gin for building powerful APIs will greatly enhance your learning experience. By following this tutorial, you will gain insight into building a scalable and distributed system to extract profile information from TikTok.
Developing a Deeper Understanding of the Website You Want to Scrape.
Before delving into writing the code, it is imperative to thoroughly analyze and understand the structure of TikTok’s website. To facilitate this process, we recommend using the convenient “Quick Javascript Switcher” Chrome plugin, available here. This invaluable tool allows you to disable and re-enable JavaScript with a single mouse-click. By doing so, we aim to optimize our scraping workflow, to increase efficiency, and to minimize costs by minimizing the reliance on JavaScript rendering.
Upon disabling JavaScript using the plugin, we will focus our attention on TikTok’s profile page — the specific page we aim to scrape. Analyzing this page thoroughly will enable us to gain a comprehensive understanding of its underlying structure, crucial elements, and relevant data points. By examining the HTML structure, identifying key tags and attributes, and inspecting the network requests triggered during page loading, we can unravel the essential information we seek to extract.
Furthermore, by scrutinizing the structure and behavior of TikTok’s profile page without the interference of JavaScript, we can ensure our scraper’s efficiency and effectiveness. Bypassing the rendering of JavaScript code allows us to directly target the necessary HTML elements and retrieve the desired data swiftly and accurately.
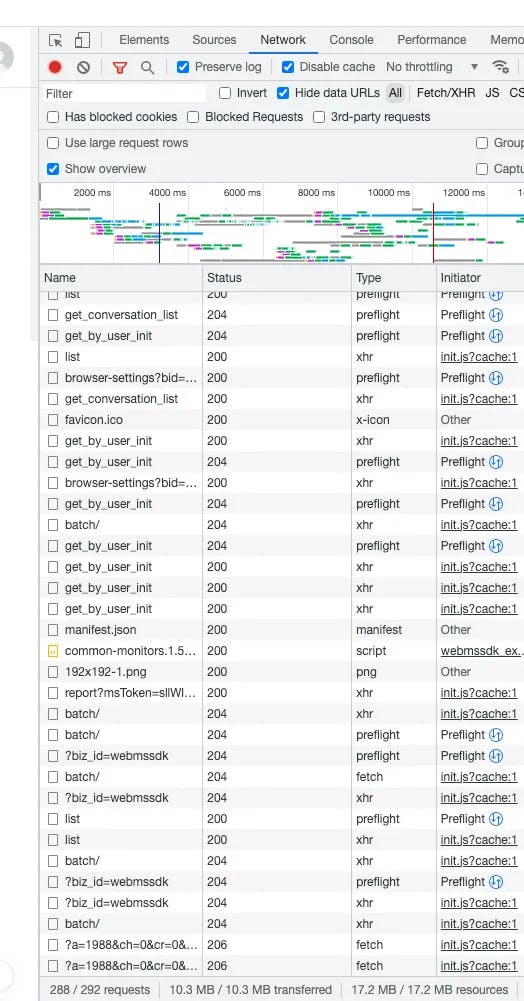
the Network of Requests in TikTok Profile Page with JavaScript Enabled
Imagine visiting a TikTok profile, such as “https://www.tiktok.com/@linisflorez09" with JavaScript enabled. You would witness approximately 300 requests being made, resulting in a whopping transfer of 10MB of data. Loading the entire page, complete with CSS style files, JavaScript files, images, and videos, takes roughly 5 seconds. Now, let’s put this into perspective: if we aim to scrape millions of data records, the total number of requests would skyrocket into the billions, while the data package would amass to over ten Terabytes. And that’s not even factoring in the computing resources consumed by headless Chrome instances. This proactive approach not only streamlines the scraping process, but also helps mitigate unnecessary expenses, ultimately saving you, your boss, or your customers substantial amounts of money.
It is crucial to acknowledge the monumental task at hand when dealing with such large-scale data scraping operations. By investing time and effort into analyzing the webpage upfront, we can discover innovative ways to extract the desired data while minimizing the number of requests, reducing data transfer size, and optimizing resource utilization. This strategic approach ensures that our scraping process is not only efficient but also cost-effective.
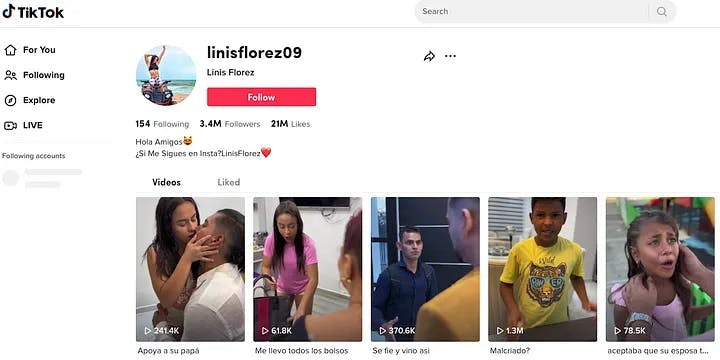
TikTok Profile Page with JavaScript Disabled
Implementing the Code for Scraping TikTok Profiles
When it comes to scraping TikTok’s profile page, the Golang built-in net/http package provides a reliable solution for making HTTP requests. If you prefer a more straightforward approach without the need for callback features like OnError` and OnResponse offered by Golang Colly, net/http is a suitable choice.
Below, you’ll find a code snippet to guide you in building your TikTok profile scraper. However, certain parts of the code are intentionally omitted to prevent potential misuse, such as sending an excessive number of requests to the TikTok platform. It’s crucial to adhere to ethical scraping practices and respect the platform’s terms of service.
To extract information from HTML pages using CSS selectors in Golang, various tutorials and resources are available that demonstrate the use of libraries like goquery. Exploring these resources will provide you with comprehensive guidance on extracting specific data points from HTML pages.
Please note that the provided code snippet is meant for reference. Ensure that you modify and augment it as per your requirements and adhere to responsible data scraping practices.
package workers
import (
"bytes"
"fmt"
"strings"
"time"
"github.com/PuerkitoBio/goquery"
"github.com/gocolly/colly/v2"
"github.com/samber/lo"
"github.com/tonywangcn/tiktok-crawler/models"
"github.com/tonywangcn/tiktok-crawler/pkg/log"
"github.com/tonywangcn/tiktok-crawler/pkg/redis"
"github.com/tonywangcn/tiktok-crawler/pkg/regex"
)
var tikTokWorker *TikTokWorker
func RunTikTokWorker(count int) {
log.Info("worker is running %d", count)
tikTokWorker = NewTikTokWorker()
go func() {
for {
if len(tikTokWorker.jobsArr) > 100 {
time.Sleep(time.Millisecond * 200)
continue
}
val := redis.LPop(tiktokJobQueue)
if val != "" {
if tikTokWorker.isJobScraped(val) {
continue
}
if err := tikTokWorker.AddJob(val); err != nil {
log.Error(err.Error())
continue
}
}
time.Sleep(time.Millisecond * 200)
}
}()
tikTokWorker.run(count)
}
func NewTikTokWorker() *TikTokWorker {
return &TikTokWorker{
Worker: New(),
}
}
func (w *TikTokWorker) parse(r *colly.Response, handler string, proxy string) *models.TikTok {
tiktok := &models.TikTok{}
tiktok.Handler = handler
doc, _ := goquery.NewDocumentFromReader(bytes.NewReader(r.Body))
title := strings.TrimSpace(doc.Find(".title-m").Text())
if title != "" || r.StatusCode != 200 {
log.Error("error found | msg %s | job %s | status code %d | proxy %s | body %s ", title, handler, r.StatusCode, proxy, string(r.Body))
return nil
}
title = strings.TrimSpace(doc.Find("[data-e2e='user-title']").Text())
if title == "" {
log.Error("error found | title is empty %s | job %s | status code %d | proxy %s | body %s ", title, handler, r.StatusCode, proxy, string(r.Body))
return nil
}
doc.Find("[data-e2e='user-subtitle']").Each(func(i int, s *goquery.Selection) {
tiktok.Username = s.Text()
})
doc.Find("[data-e2e='following-count']").Each(func(i int, s *goquery.Selection) {
followingCount, err := regex.ParseStrToInt(s.Text())
if err != nil {
log.Error("failed to parse following count to int | %s | err: %s", s.Text(), err.Error())
return
}
tiktok.FollowingCount = followingCount
})
doc.Find("[data-e2e='followers-count']").Each(func(i int, s *goquery.Selection) {
followersCount, err := regex.ParseStrToInt(s.Text())
if err != nil {
log.Error("failed to parse followers count to int | %s | err: %s", s.Text(), err.Error())
return
}
tiktok.FollowersCount = followersCount
})
doc.Find("[data-e2e='likes-count']").Each(func(i int, s *goquery.Selection) {
likesCount, err := regex.ParseStrToInt(s.Text())
if err != nil {
log.Error("failed to parse likes count to int | %s | err: %s", s.Text(), err.Error())
return
}
tiktok.LikesCount = likesCount
})
doc.Find("[data-e2e='user-bio']").Each(func(i int, s *goquery.Selection) {
tiktok.Bio = s.Text()
})
doc.Find("[data-e2e='user-link'] span").Each(func(i int, s *goquery.Selection) {
tiktok.Links = append(tiktok.Links, s.Text())
})
doc.Find("[class*='ImgAvatar']").Each(func(i int, s *goquery.Selection) {
profile, ok := s.Attr("src")
if ok {
tiktok.ProfilePic = profile
}
})
doc.Find("svg [fill-rule='evenodd']").Each(func(i int, s *goquery.Selection) {
_, ok := s.Attr("fill")
if ok {
tiktok.BlueTick = true
}
})
tiktok.Emails = regex.ParseEmails(tiktok.Bio)
if tiktok.LikesCount == 0 && tiktok.FollowersCount == 0 {
redis.LPush(tiktokJobQueue, handler)
log.Error(`failed to scrape data from handler %s | %+v | resp body %s`, handler, tiktok, string(r.Body))
return nil
}
return tiktok
}
func (w *TikTokWorker) worker(job string) {
w.markJobScraped(job)
c := newCollector()
c.SetRequestTimeout(30 * time.Second)
proxy := getProxy()
if proxy != "" {
c.SetProxy(proxy)
}
c.OnError(func(r *colly.Response, err error) {
log.Error("error found | msg %s | job %s | url %s | status code %d | proxy %s | resp %s", err.Error(), job, r.Request.URL, r.StatusCode, proxy, string(r.Body))
w.incrError(job)
if r.StatusCode == 404 {
return
}
w.AddJob(job)
})
c.OnResponse(func(r *colly.Response) {
tiktok := w.parse(r, job, proxy)
if tiktok == nil {
w.incrError(job)
w.AddJob(job)
return
}
log.Info("TikTok %+v", tiktok)
if err := tiktok.Insert(); err != nil {
log.Error(err.Error())
} else {
w.incrSuccess()
log.Info("Tiktok handler %s is saved into db successfully !", job)
}
})
c.OnRequest(func(r *colly.Request) {
r.Headers.Set("referer", "https://www.google.com")
r.Headers.Set("accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7")
r.Headers.Set("accept-language", "en-CA,en;q=0.9")
r.Headers.Set("cache-control", "no-cache")
r.Headers.Set("dnt", "1")
r.Headers.Set("pragma", "no-cache")
r.Headers.Set("sec-fetch-dest", "document")
r.Headers.Set("sec-fetch-mode", "navigate")
r.Headers.Set("sec-fetch-site", "none")
r.Headers.Set("sec-fetch-user", "?1")
r.Headers.Set("upgrade-insecure-requests", "1")
log.Info("Visiting %s", r.URL.String())
})
c.Visit(fmt.Sprintf("https://www.tiktok.com/@%s?lang=en", job))
}Discovering the Entry Points for Popular Videos and Profiles
By now, we have completed the TikTok profile scraper. However, there’s more to explore. How can we find millions of top profiles to scrape? That’s precisely what I’ll discuss next.
If you visit the TikTok homepage at https://www.tiktok.com/, you’ll notice four sections on the top left: For You, Following, Explore, and Live. Clicking on the For You and Explore sections will yield random popular videos each time. Hence, these two sections serve as entry points for us to discover a vast number of viral videos. Let’s analyze them individually:
Explore Page
Once we navigate to the explore page, it’s advisable to clean up the network section of DevTools for better clarity before proceeding with any further operations.
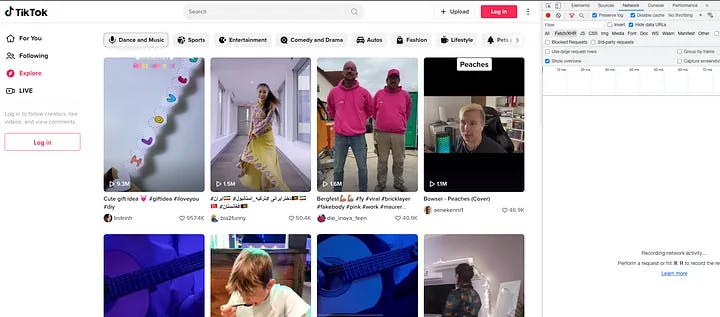
Explore page with all requests under Network section cleared
To ensure accurate filtering of requests, remember to select the Fetch/XHR option. This selection will exclude any requests that are not made by JavaScript from the frontend. Once you have everything set up, proceed by scrolling down the explore page. As you do so, TikTok will continue recommending viral videos based on factors such as your country and behavior. Simultaneously, keep a close eye on the network panel. Your goal is to locate the specific request containing the keyword “explore” among the numerous requests being made.
Initially, it may not be immediately clear which exact request to focus on. Take your time and carefully inspect each request. We are looking for the request that returns essential information, such as author details, video content, view count, and other relevant data. Although the inspection process may require some patience, it is definitely worth the effort.
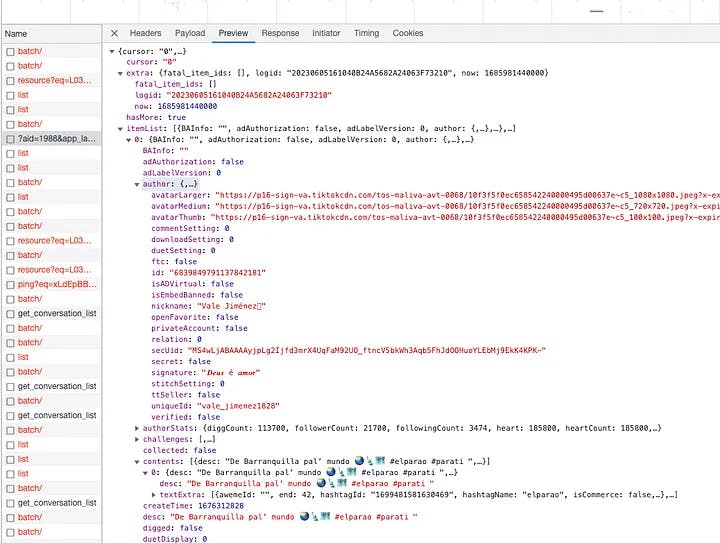
The response of a request from explore page.
Continuing with the process, scroll down the explore page to explore more viral videos tailored to your country, behavior, and other factors. As you delve deeper, among the numerous requests being made, you will eventually come across a specific request containing the keyword explore. This particular request is the one we are searching for to extract the desired data. To proceed, right-click on this request and select the option Copy as cURL, as illustrated in the accompanying screenshot. By choosing this option, you can capture the request details in the form of a cURL command, which will serve as a valuable resource for further analysis and integration into your scraping workflow.
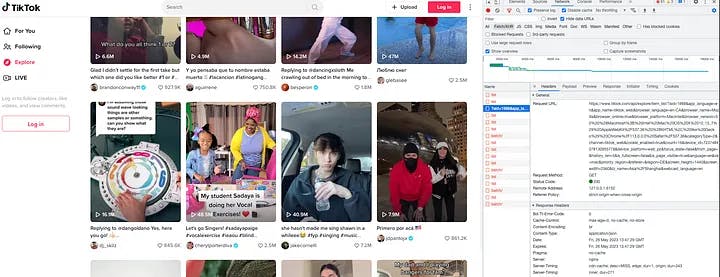
Scroll down the explore page until you find the correct request.
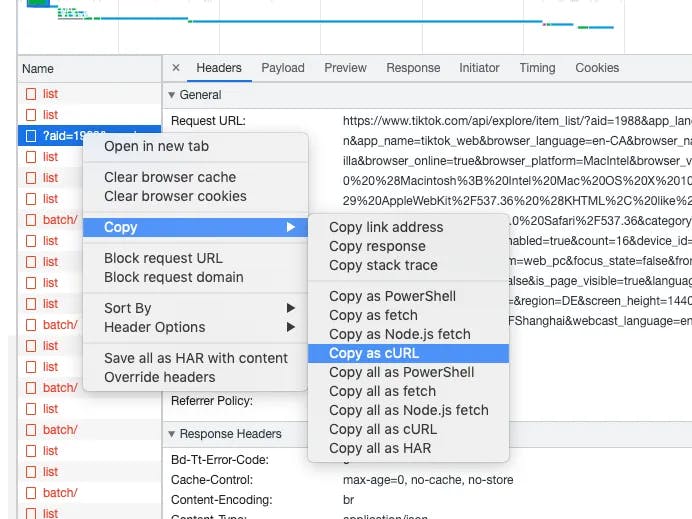
Copy the request as cURL
Using the previously identified request, we can import it into Postman to simulate the same request. Upon clicking the “Send” button, we should receive a similar response. This indicates that the request does not require the bothersome CSRF token for encryption and can be sent multiple times to obtain different results.
To further explore the request, we will examine it in Postman. Within the Params and Headers panel, you have the option to uncheck various boxes and then click the Send button. By doing so, you can verify if the response is successfully returned without including specific parameters. If the response is indeed returned, it implies that the corresponding parameter can be omitted in further development and requests. This step allows us to determine which parameters are required and which ones can be excluded for more efficient scraping.
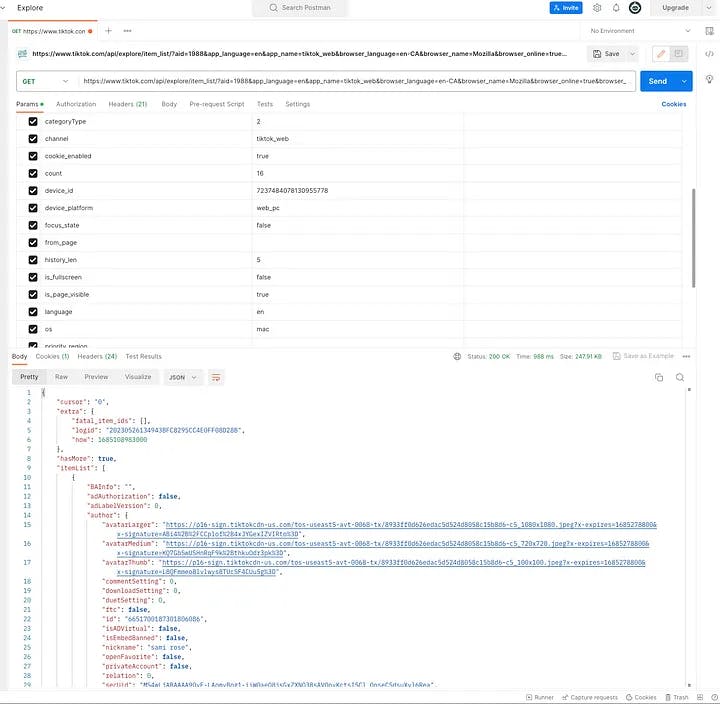
Import the cURL from above step to Postman, and click
Sendbutton
Before diving into the code implementation, there is an essential piece of information we need to acquire — the category IDs. On the explore page, you will find a variety of categories displayed at the top, including popular ones like Dance and Music, Sports, and Entertainment. These categories play a crucial role in targeting specific types of content for scraping.
To proceed, we will follow a similar approach as mentioned earlier. Begin by cleaning up the network session to enhance clarity and ensure a focused analysis. Then, systematically click on each category button, one by one, and observe the value of the categoryType parameter associated with each request. By examining the categoryType values, we can identify the corresponding IDs for each category.
This step is vital as it enables us to tailor our scraping process to specific categories of interest. By retrieving the relevant category IDs, we can precisely target the desired content and extract the necessary data. So, take your time to explore and document the category IDs, as it will significantly enhance the effectiveness of your scraping implementation.
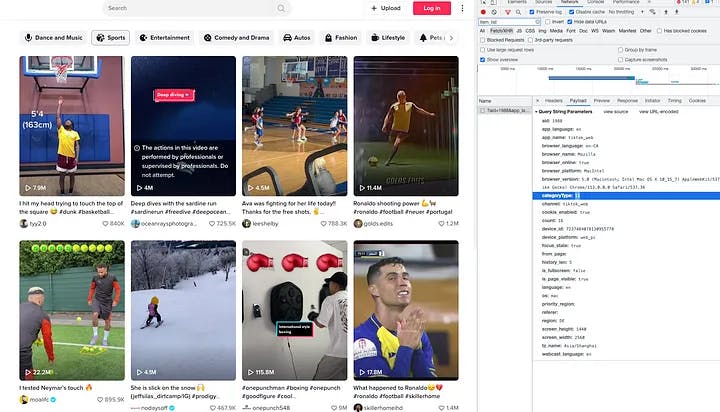
Click the second section
Sportsand find the corresponding categoryType of Sports
In the end, after performing the necessary analysis, we will compile a comprehensive map that associates each category type with its unique ID:
var categoryTypeMap = map[string]string{
"1": "comoedy & drama",
"2": "dance & music",
"3": "relationship",
"4": "pet & nature",
"5": "lifestyle",
"6": "society",
"7": "fashion",
"8": "enterainment",
"10": "informative",
"11": "sport",
"12": "auto",
}At this point, we have almost completed the analysis of the explore page, and we are ready to begin the code implementation phase. To simplify the process and save time, there are several online services available that can assist us in converting JSON data into Go struct format. One such service that I highly recommend is https://mholt.github.io/json-to-go/.
This convenient tool allows us to paste the JSON response obtained from the explore page and automatically generates the corresponding Go struct representation. By utilizing this service, we can effortlessly convert the retrieved JSON data into structured Go objects, which will greatly facilitate data manipulation and extraction in our code.
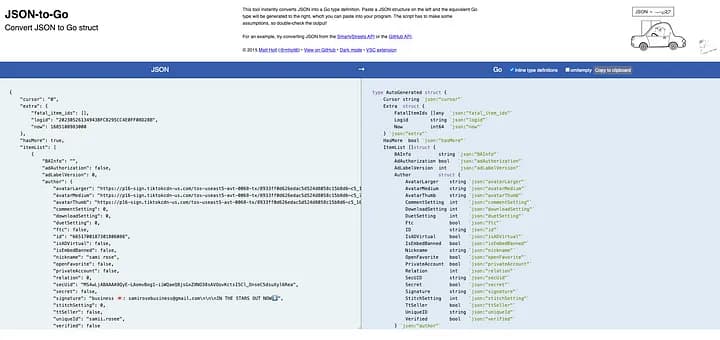
Copy the JSON response from the Postman response to any online
JSON to Go structwebsite, and convert it to Go struct for later use.
The criteria I have set for determining popular profiles on TikTok is based on two factors: the number of likes on their content and the number of followers they have. Specifically, I consider a profile to be popular if they have any content with at least 250K likes or if they have accumulated at least 10K followers. These thresholds help identify profiles that have gained significant attention and engagement on the platform.
The key information I aim to extract from these popular profiles includes their unique identifier (ID), which serves as an input variable scraping profile details, and their follower count, which provides insights into their audience reach and influence. Additionally, I am interested in capturing the “digg” count of their videos, which represents the number of times users have interacted with and appreciated their content. These pieces of information offer valuable metrics to assess the popularity and impact of TikTok profiles.
It is worth noting that while the above-mentioned information is essential for my specific project, you have the flexibility to customize and retain any additional data that aligns with the requirements and objectives of your own undertaking. This allows you to tailor the scraping process to suit your unique needs and extract the most relevant information for your analysis or application.
type TikTokRespItem struct {
Author struct {
Nickname string `json:"nickname"`
Signature string `json:"signature"`
UniqueID string `json:"uniqueId"`
PrivateAccount bool `json:"privateAccount"`
} `json:"author"`
AuthorStats struct {
DiggCount int `json:"diggCount"`
FollowerCount int `json:"followerCount"`
FollowingCount int `json:"followingCount"`
Heart int `json:"heart"`
HeartCount int `json:"heartCount"`
VideoCount int `json:"videoCount"`
} `json:"authorStats"`
Stats struct {
CollectCount int `json:"collectCount"`
CommentCount int `json:"commentCount"`
DiggCount int `json:"diggCount"`
PlayCount int `json:"playCount"`
ShareCount int `json:"shareCount"`
} `json:"stats"`
}
type TikTokResp struct {
Cursor string `json:"cursor"`
HasMore bool `json:"hasMore"`
ItemList []TikTokRespItem `json:"itemList"`
StatusCode int `json:"statusCode"`
}For the parameters inside the getUrl function, you have the flexibility to remove or customize any specific parameters based on the analysis we conducted earlier. This allows you to fine-tune the request and retrieve more accurate results from the explore response. In this demonstration, I have chosen to keep all the parameters as they are, except for categoryType, which I have left as a variable. This approach will enable us to scrape data from all categories, providing a comprehensive view of the TikTok profiles we intend to extract.
func RunTikTokExploreWorker(count int) {
for categoryType, name := range categoryTypeMap {
log.Info("worker is running %d , categoryType %s, name %s", count, categoryType, name)
tiktokExploreWorker = NewTikTokExploreWorker()
tiktokExploreWorker.run(count, categoryType)
}
}
func (w *TikTokExploreWorker) getUrl(categoryType string) string {
var params = url.Values{}
params.Add("aid", "1988")
params.Add("app_language", "en")
params.Add("app_name", "tiktok_web")
params.Add("browser_language", "en-US")
params.Add("battery_info", "1")
params.Add("browser_name", "Mozilla")
params.Add("browser_online", "true")
params.Add("browser_platform", "Linux x86_64")
params.Add("browser_version", "5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.109 Safari/537.36")
params.Add("channel", "tiktok_web")
params.Add("cookie_enabled", "true")
params.Add("categoryType", categoryType)
params.Add("device_id", crypto.RandomStringNumber(19))
params.Add("device_platform", "web_pc")
params.Add("focus_state", "true")
params.Add("from_page", "hashtag")
params.Add("count", "16")
params.Add("is_fullscreen", "false")
params.Add("is_page_visible", "true")
params.Add("language", "en")
params.Add("os", "mac")
params.Add("priority_region", "")
params.Add("referer", "https://www.tiktok.com/explore?lang=en")
params.Add("region", "US")
params.Add("screen_height", "1120")
params.Add("screen_width", "1792")
params.Add("tz_name", "Europe/Bucharest")
params.Add("webcast_language", "en")
u, _ := url.ParseRequestURI("https://www.tiktok.com")
u.Path = "/api/explore/item_list/"
u.RawQuery = params.Encode()
return fmt.Sprintf("%v", u)
}
func (w *TikTokExploreWorker) worker(categoryType string) {
c := newCollector()
c.SetRequestTimeout(30 * time.Second)
u := w.getUrl(categoryType)
proxy := getProxy()
if proxy != "" {
c.SetProxy(proxy)
}
c.OnError(func(r *colly.Response, err error) {
log.Error("error %s | proxy %s | retrying", err.Error(), proxy)
r.Request.Retry()
})
c.OnResponse(func(r *colly.Response) {
var resp TikTokResp
if r.StatusCode != 200 {
log.Error("status code is not 200 %d | tag %s", r.StatusCode, categoryType)
w.incrError()
return
}
if err := json.Unmarshal(r.Body, &resp); err != nil {
log.Error("TikTokExploreWorker | unmarshal error %s | resp body %s |", err.Error(), string(r.Body))
w.incrError()
return
}
if resp.StatusCode > 0 {
log.Error("status code is not 0 %d | proxy %s", resp.StatusCode, proxy)
w.incrError()
return
}
items := lo.Filter(resp.ItemList, func(item TikTokRespItem, _ int) bool {
return item.Stats.DiggCount > 25000
})
if len(items)*3 < len(resp.ItemList) {
log.Error("digg count is less than 25000 length %d total %d | skipping ", len(items), len(resp.ItemList))
return
}
for _, item := range resp.ItemList {
if item.AuthorStats.FollowerCount > 10000 {
log.Info("follower count is more than 10000 | author name %s, unique id %s resp.Cursor %s ", item.Author.Nickname, item.Author.UniqueID, resp.Cursor)
tikTok := &models.TikTok{}
tikTok.Handler = item.Author.UniqueID
if !tikTok.IsJobScraped() {
log.Info("tiktok job is not scraped, pushing to tiktokJobQueue | author name %s, unique id %s", item.Author.Nickname, item.Author.UniqueID)
redis.LPush(tiktokJobQueue, item.Author.UniqueID)
}
}
if item.Stats.DiggCount > 250000 {
log.Info("digg count is more than 250000 | author name %s, unique id %s resp.Cursor %s ", item.Author.Nickname, item.Author.UniqueID, resp.Cursor)
tikTok := &models.TikTok{}
tikTok.Handler = item.Author.UniqueID
if !tikTok.IsJobScraped() {
redis.LPush(tiktokJobQueue, item.Author.UniqueID)
}
}
}
})
c.OnRequest(func(r *colly.Request) {
r.Headers.Set("referer", "https://www.tiktok.com/explore?lang=en")
r.Headers.Set("accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7")
r.Headers.Set("accept-language", "en-CA,en;q=0.9")
r.Headers.Set("cache-control", "no-cache")
r.Headers.Set("dnt", "1")
r.Headers.Set("pragma", "no-cache")
r.Headers.Set("sec-fetch-dest", "document")
r.Headers.Set("sec-fetch-mode", "navigate")
r.Headers.Set("sec-fetch-site", "none")
r.Headers.Set("sec-fetch-user", "?1")
log.Info("Visiting %s ", r.URL.String())
})
c.Visit(u)
}Building an API service to monitor scraper stats
By now, we have completed the majority of the TikTok scraper. As we are utilizing Redis as the message queue to store tasks, it is crucial to monitor key statistics to ensure the smooth functioning of the scraper. We need to track metrics such as the number of times each category has been scraped, the count of successes and failures, and the remaining tasks in the job queue. To achieve this, it is necessary to build a service that offers an API endpoint for querying the statistics information at any time. Additionally, to safeguard sensitive stats, it is advisable to secure the endpoints, implementing appropriate authentication and authorization measures. This will ensure that only authorized individuals can access the scraper’s monitoring API and maintain the confidentiality of the collected data.
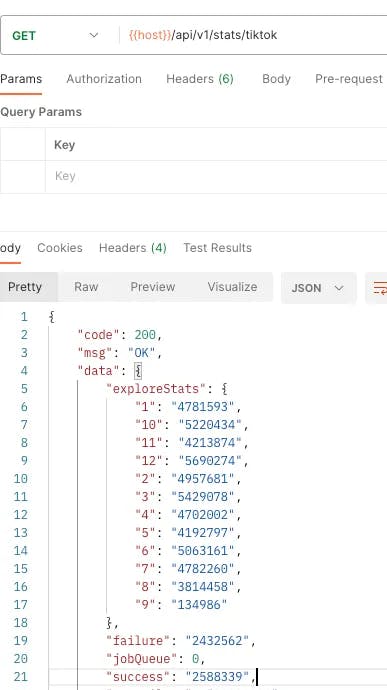
Scraper statistics returned through API endpoint
Here, we are going to complete the final part of the code, which is the main function. To simplify the deployment process, we will compile all the Golang code into a single binary file and package it into a Docker image. However, a question arises: How can we deploy different services, such as the profile scraper, explore scraper, and API service, with different numbers of replicas?
To address this challenge, we will use the main function with different arguments when running the tiktok-crawler binary. By modifying the workerMap, we can add as many different types of workers as we need to expand the functionality. For example, for the profile scraper, we may require 20 workers and 3 replicas, while for the explore scraper, we may need 40 workers and 4 replicas. The flexibility of the main function allows us to configure the desired number of workers for each scraper. By default, we set the number of workers for each scraper to 20.
package main
import (
"flag"
"os"
"os/signal"
"syscall"
"github.com/tonywangcn/tiktok-crawler/pkg/log"
"github.com/tonywangcn/tiktok-crawler/workers"
)
var workerMap map[string]func(count int) = map[string]func(count int){
"tiktok": workers.RunTikTokWorker,
"tiktok-exp": workers.RunTikTokExploreWorker,
}
func main() {
shutdown := make(chan int)
sigChan := make(chan os.Signal, 1)
signal.Notify(sigChan, os.Interrupt, syscall.SIGTERM, syscall.SIGINT)
go func() {
<-sigChan
log.Info("Shutting down...")
shutdown <- 1
}()
var worker string
var isServer bool
var count int
flag.BoolVar(&isServer, "s", false, "Run as server")
flag.StringVar(&worker, "w", "tiktok", "Choose the worker to run")
flag.IntVar(&count, "c", 20, "Number of workers to run")
flag.Parse()
if isServer {
go Server()
} else {
f, ok := workerMap[worker]
if !ok {
panic("worker not found")
}
f(count)
}
<-shutdown
}package main
import (
"fmt"
"log"
"net/http"
"github.com/gin-gonic/gin"
"github.com/tonywangcn/tiktok-crawler/pkg/setting"
"github.com/tonywangcn/tiktok-crawler/routers"
)
func Server() {
gin.SetMode(setting.ServerSetting.RunMode)
routersInit := routers.InitRouter()
readTimeout := setting.ServerSetting.ReadTimeout
writeTimeout := setting.ServerSetting.WriteTimeout
endPoint := fmt.Sprintf(":%d", setting.ServerSetting.HttpPort)
maxHeaderBytes := 1 << 20
server := &http.Server{
Addr: endPoint,
Handler: routersInit,
ReadTimeout: readTimeout,
WriteTimeout: writeTimeout,
MaxHeaderBytes: maxHeaderBytes,
}
log.Printf("[info] start http server listening %s", endPoint)
server.ListenAndServe()
}Building a Docker Image and Deploying it into a Kubernetes Cluster
FROM golang:1.19 AS builder
ENV USER=appuser
ENV UID=10001
RUN adduser \
--disabled-password \
--gecos "" \
--home "/nonexistent" \
--shell "/sbin/nologin" \
--no-create-home \
--uid "${UID}" \
"${USER}"
ARG WORKDIR=/go/src/github.com/tonywangcn/tiktok-crawler/
WORKDIR ${WORKDIR}
COPY . .
RUN CGO_ENABLED=0 GOOS=linux GOARCH=amd64 go build -a -installsuffix cgo -o tiktok-crawler .
FROM gcr.io/distroless/static-debian11
ENV ENV=PROD
ARG WORKDIR=/code/
ARG OLD_WORKDIR=/go/src/github.com/tonywangcn/tiktok-crawler/
WORKDIR ${WORKDIR}
COPY --from=builder ${OLD_WORKDIR}tiktok-crawler ${WORKDIR}
COPY ./conf ./conf/Here is the Dockerfile that enables us to build the binary file and package it into a Docker image, which can then be deployed into a Kubernetes (k8s) cluster.
Before deploying the code into a Kubernetes (k8s) cluster, it’s advisable to test the functionality of both the code and the Docker image locally using Docker Compose. Docker Compose allows us to define and manage multi-container applications. In this case, we can use the provided docker-compose.yml file.
By running the command docker-compose up — scale tiktok-profile=3 — scale tiktok-server=1 — scale tiktok-explore=5 -d, you can launch multiple instances of the desired services. This command allows you to scale up or down the number of replicas for each service as needed. It ensures that the services, such as tiktok-profile, tiktok-server, and tiktok-explore, are properly orchestrated and running concurrently.
Testing the code and Docker image locally with Docker Compose allows for a comprehensive evaluation of the application’s behavior and performance before deploying it into the production Kubernetes cluster. It helps ensure that the application functions as expected and can handle the desired scaling requirements.
version: "3.5"
services:
tiktok-profile:
image: golang:1.19
volumes:
- "./:/go/src/github.com/tonywangcn/tiktok-crawler"
environment:
- GO111MODULE=on
- ENV=DEV
working_dir: /go/src/github.com/tonywangcn/tiktok-crawler
command: bash -c "go build . && ./tiktok-crawler -w tiktok"
restart: always
logging:
driver: "json-file"
options:
max-size: "10m"
max-file: "3"
tiktok-server:
image: golang:1.19
volumes:
- "./:/go/src/github.com/tonywangcn/tiktok-crawler"
environment:
- GO111MODULE=on
- ENV=DEV
ports:
- 8080:8080
working_dir: /go/src/github.com/tonywangcn/tiktok-crawler
command: bash -c "go build . && ./tiktok-crawler -s true"
restart: always
logging:
driver: "json-file"
options:
max-size: "10m"
max-file: "3"
tiktok-explore:
image: golang:1.19
volumes:
- "./:/go/src/github.com/tonywangcn/tiktok-crawler"
environment:
- GO111MODULE=on
- ENV=DEV
working_dir: /go/src/github.com/tonywangcn/tiktok-crawler
command: bash -c "go build . && ./tiktok-crawler -w tiktok-exp"
restart: always
logging:
driver: "json-file"
options:
max-size: "10m"
max-file: "3"After executing the provided command, you will observe that the specified number of profile scrapers, explore scrapers, and API servers are successfully launched and operational.

Running scraper services locally with docker-compose
Deploying the Scraper to Kubernetes Cluster
Everything is prepared for the next stage, which involves deploying the application to a Kubernetes (k8s) cluster. Below is a sample k8s deployment file for your reference. You have the flexibility to customize the number of replicas for the scrapers and adjust the parameters for the scraper command as needed. It is important to note that the value for alb.ingress.kubernetes.io/subnets in the Ingress controller should be set according to the subnets associated with your k8s cluster during its creation. This ensures proper networking configuration for the Ingress controller.
apiVersion: apps/v1
kind: Deployment
metadata:
name: tiktok-profile
spec:
replicas: 4
selector:
matchLabels:
app: tiktok-profile
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
labels:
app: tiktok-profile
spec:
containers:
- name: tiktok-profile
image: tiktok-crawler:20230608131447
command: ["./tiktok-crawler"]
args: ["-w", "tiktok","-c", "40"]
imagePullPolicy: IfNotPresent
volumeMounts:
- name: go-crawler-conf-volume
mountPath: /code/conf/prod.ini
subPath: prod.ini
resources:
limits:
cpu: 300m
memory: 300Mi
volumes:
- name: go-crawler-conf-volume
configMap:
name: go-crawler-conf
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: tiktok-explore
spec:
replicas: 5
selector:
matchLabels:
app: tiktok-explore
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
labels:
app: tiktok-explore
spec:
containers:
- name: tiktok-explore
image: tiktok-crawler:20230608131447
command: ["./tiktok-crawler"]
args: ["-w", "tiktok-exp", "-c", "40"]
imagePullPolicy: IfNotPresent
volumeMounts:
- name: go-crawler-conf-volume
mountPath: /code/conf/prod.ini
subPath: prod.ini
resources:
limits:
cpu: 1500m
memory: 2500Mi
volumes:
- name: go-crawler-conf-volume
configMap:
name: go-crawler-confapiVersion: apps/v1
kind: Deployment
metadata:
name: go-server
spec:
replicas: 1
selector:
matchLabels:
app: go-server
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
labels:
app: go-server
spec:
containers:
- name: go-server
image: tiktok-crawler:20230608131447
command: ["./tiktok-crawler"]
args: ["-s", "true"]
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8080
volumeMounts:
- name: go-crawler-conf-volume
mountPath: /code/conf/prod.ini
subPath: prod.ini
resources:
limits:
cpu: 500m
memory: 500Mi
volumes:
- name: go-crawler-conf-volume
configMap:
name: go-crawler-conf
---
apiVersion: v1
kind: Service
metadata:
name: go-server-svc
namespace: default
spec:
ports:
- name: go-server
targetPort: 8080
port: 8080
selector:
app: go-server
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: go-server-ingress
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/subnets: subnet-0e057e2872653c913
alb.ingress.kubernetes.io/load-balancer-attributes: idle_timeout.timeout_seconds=600
spec:
ingressClassName: alb
rules:
- http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: go-server-svc
port:
number: 8080To optimize cost while running the scraper, it is recommended to utilize Spot Instances when adding a new node group. Spot Instances offer a significant cost advantage, as they are typically priced 20%-90% lower than On-Demand instances. Since the scraper is designed to be stateless and can be terminated at any time, Spot Instances are suitable for this use case. By leveraging Spot Instances, you can achieve substantial cost savings while maintaining the required functionality of the scraper.
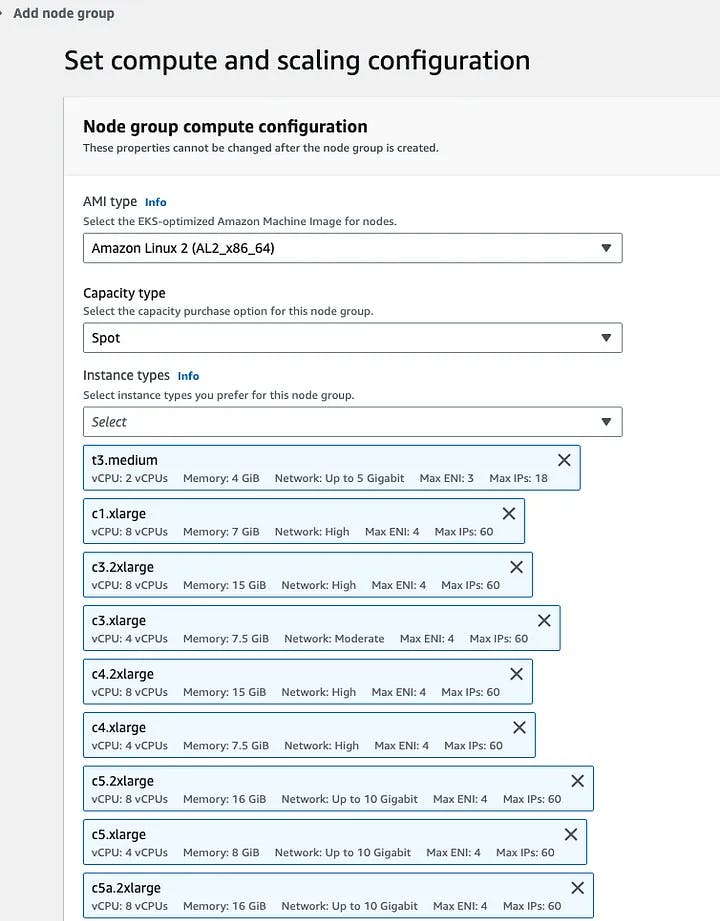
Set compute and scaling configuration for new node group
Once the node group has been successfully created and the state of the nodes has changed to ready, you are ready to deploy the scraper using the command kubectl apply -f deployment.yaml. This command will apply the configurations specified in the deployment file to the Kubernetes cluster. It will ensure that the desired number of replicas for the scraper services are up and running.
One of the advantages of using Kubernetes is its flexibility in scaling the number of replicas. You can easily adjust the number of workers that should be running at any given time by updating the deployment configuration. This allows you to scale up or down the number of scraper workers based on the workload or performance requirements.
By executing the appropriate kubectl commands, you have the flexibility to manage and control the deployment of the scraper services within the Kubernetes cluster, ensuring optimal performance and resource utilization.
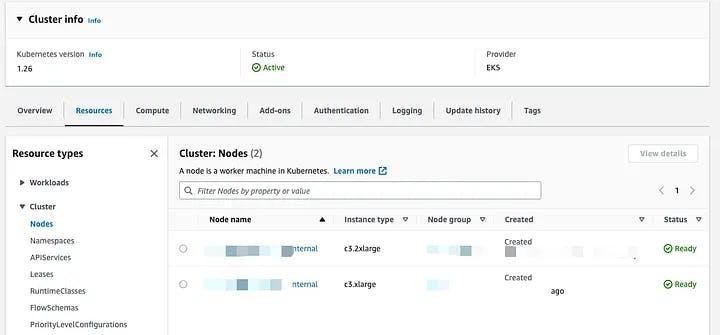
Nodes state page in AWS Kubernetes cluster
Based on my extensive experience with the scraper, I have observed that the initial speed can reach an impressive rate of up to 1 million records per day when using the criteria I have set. However, it’s important to note that as time progresses, the speed may gradually decrease to a few thousand records per day. This decline occurs due to the nature of the explore page, where many of the popular contents have been created months ago. As we continue to scrape more profiles, we naturally cover a significant portion of the popular ones. Consequently, it becomes increasingly challenging to discover new viral content.
Considering this, it is advisable to consider temporarily halting the scraper for a few weeks or even longer. By pausing the scraping process, you allow time for new viral content to emerge and accumulate. Once a sufficient period has passed, restarting the scraper will help maintain efficiency and optimize costs, as you will be able to focus on capturing the latest popular profiles and videos.
With the successful completion of the TikTok scraper and its deployment in a distributed system using Kubernetes, we have achieved a robust and scalable solution. The combination of scraping techniques, data processing, and deployment infrastructure has allowed us to harness the full potential of TikTok’s platform. If you have any questions regarding this article or any suggestions for future articles, I encourage you to leave a comment below. Additionally, I am available for remote work or contracts, so please feel free to reach out to me via email.