Support me on Patreon to write more tutorials like this!


The internet, in many ways, has a memory. From archived versions of old websites to search engine caches, there's often a way to dig into the past and uncover information—even for websites that are no longer active. You may have heard of the Internet Archive, a popular tool for exploring the history of the web, which has experienced outages lately due to hacks and other challenges. But what if there was no Internet Archive? Does the internet still "remember" these sites?
In this article, we'll dive into a study of the top 10 million domains and reveal a surprising finding: over a quarter of them—27.6%—are effectively dead. Below, I'll walk you through the steps and infrastructure involved in analyzing these domains, along with the system requirements, code snippets, and statistical results of this research.
The Challenge: Analyzing 10 Million Domains
Thanks to resources like DomCop, we can access a list of the top 10 million domains, which serves as our starting point. Processing such a large volume of URLs requires significant computing resources, parallel processing, and optimized handling of HTTP requests.
To get accurate results quickly, we needed a well-designed scraper capable of handling millions of requests in minutes. Here’s a breakdown of our approach and the system design.
System Design for High-Volume Domain Scraping
To analyze 10 million domains in a reasonable timeframe, we set a target of completing the task in 10 minutes. This required a system that could process approximately 16,667 requests per second. By splitting the load across 100 workers, each would need to handle around 167 requests per second.
1. Efficient Queue Management with Redis
Redis, with its capability of handling over 10,000 requests per second easily, played a key role in managing the job queue. However, even with Redis, tracking status codes from millions of domains can overload the system. To prevent this, we utilized Redis pipelines, allowing multiple jobs to be processed simultaneously and reducing the load on our Redis cluster.
// SPopN retrieves multiple items from a Redis set efficiently.
func SPopN(key string, n int) []string {
pipe := Redis.Pipeline()
for i := 0; i < n; i++ {
pipe.SPop(ctx, key)
}
cmders, err := pipe.Exec(ctx)
if err != nil { return nil }
results := make([]string, 0, n)
for _, cmder := range cmders {
if spopCmd, ok := cmder.(*redis.StringCmd); ok {
val, err := spopCmd.Result()
if err == nil && val != "" { results = append(results, val) }
}
}
return results
}Using this method, we could pull large batches from Redis with minimal impact on performance, fetching up to 100 jobs at a time.
func (w *Worker) fetchJobs() {
for {
if len(w.Jobs) > 100 {
time.Sleep(time.Second)
continue
}
jobs := SPopN(w.Name+jobQueue, 100)
for _, job := range jobs {
w.AddJob(job)
}
}
}2. Optimizing DNS Requests
To resolve domains efficiently, we used multiple public DNS servers (e.g., Google DNS, Cloudflare) and handled up to 16,667 requests per second. Public DNS servers typically throttle large volumes of requests, so we implemented error handling and retries for DNS timeouts and throttling errors.
var dnsServers = []string{
"8.8.8.8", "8.8.4.4", "1.1.1.1", "1.0.0.1", "208.67.222.222", "208.67.220.220",
}By balancing the load across multiple servers, we could avoid rate limits imposed by individual DNS providers.
3. HTTP Request Handling
To check domain statuses, we attempted direct HTTP/HTTPS requests to each IP address. The following code retries with HTTPS if the HTTP request encounters a protocol error.
func (w *Worker) worker(job string) {
var ips []net.IPAddr
var err error
var customDNSServer string
for retry := 0; retry < 5; retry++ {
customDNSServer = dnsServers[rand.Intn(len(dnsServers))]
resolver := &net.Resolver{
PreferGo: true,
Dial: func(ctx context.Context, network, address string) (net.Conn, error) {
d := net.Dialer{}
return d.DialContext(ctx, "udp", customDNSServer+":53")
},
}
ctx, cancel := context.WithTimeout(context.Background(), 10*time.Second)
defer cancel()
ips, err = resolver.LookupIPAddr(ctx, job)
if err == nil && len(ips) > 0 {
break
}
log.Printf("Retry %d: Failed to resolve %s on DNS server: %s, error: %v", retry+1, job, customDNSServer, err)
}
if err != nil || len(ips) == 0 {
log.Printf("Failed to resolve %s on DNS server: %s after retries, error: %v", job, customDNSServer, err)
w.updateStats(1000)
return
}
customDialer := &net.Dialer{
Timeout: 10 * time.Second,
}
customTransport := &http.Transport{
DialContext: func(ctx context.Context, network, addr string) (net.Conn, error) {
port := "80"
if strings.HasPrefix(addr, "https://") {
port = "443"
}
return customDialer.DialContext(ctx, network, ips[0].String()+":"+port)
},
}
client := &http.Client{
Timeout: 10 * time.Second,
Transport: customTransport,
CheckRedirect: func(req *http.Request, via []*http.Request) error {
return http.ErrUseLastResponse
},
}
req, err := http.NewRequestWithContext(context.Background(), "GET", "http://"+job, nil)
if err != nil {
log.Printf("Failed to create request: %v", err)
w.updateStats(0)
return
}
req.Header.Set("User-Agent", userAgent)
resp, err := client.Do(req)
if err != nil {
if urlErr, ok := err.(*url.Error); ok && strings.Contains(urlErr.Err.Error(), "http: server gave HTTP response to HTTPS client") {
log.Printf("Request failed due to HTTP response to HTTPS client: %v", err)
// Retry with HTTPS
req.URL.Scheme = "https"
customTransport.DialContext = func(ctx context.Context, network, addr string) (net.Conn, error) {
return customDialer.DialContext(ctx, network, ips[0].String()+":443")
}
resp, err = client.Do(req)
if err != nil {
log.Printf("HTTPS request failed: %v", err)
w.updateStats(0)
return
}
} else {
log.Printf("Request failed: %v", err)
w.updateStats(0)
return
}
}
defer resp.Body.Close()
log.Printf("Received response from %s: %s", job, resp.Status)
w.updateStats(resp.StatusCode)
}Deployment Strategy
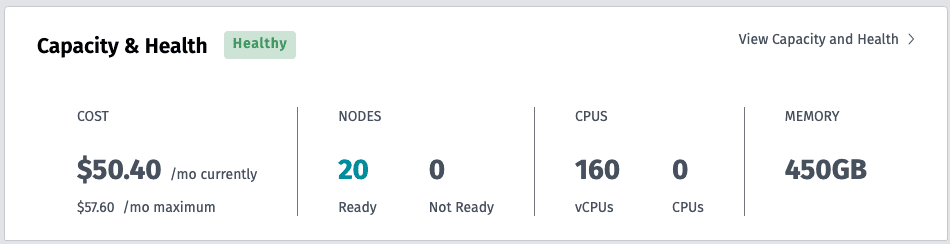
Our scraping deployment consisted of 400 worker replicas, each handling 200 concurrent requests. This configuration required 20 instances, 160 vCPUs, and 450GB of memory. With CPU usage at only around 30%, the setup was efficient and cost-effective, as shown below.
apiVersion: apps/v1
kind: Deployment
metadata:
name: worker
spec:
replicas: 400
...
containers:
- name: worker
image: ghcr.io/tonywangcn/ten-million-domains:20241028150232
resources:
limits:
memory: "2Gi"
cpu: "1000m"
requests:
memory: "300Mi"
cpu: "300m"The approximate cost for this setup was around $0.0116 per 10 million requests, totaling less than $1 for the entire analysis.
Data Analysis: How Many Sites Are Actually Accessible?
The status code data from the scraper allowed us to classify domains as "accessible" or "inaccessible." Here’s the criteria used:
- Accessible: Status codes other than 1000 (DNS not found), 0 (timeout), 404 (not found), or 5xx (server error).
- Inaccessible: Domains with the status codes above, indicating they are either unreachable or no longer in service.
accessible_condition = (
(df["status_code"] != 1000) &
(df["status_code"] != 0) &
(df["status_code"] != 404) &
~df["status_code"].between(500, 599)
)
inaccessible_condition = ~accessible_conditionAfter aggregating the results, we found that 27.6% of the domains were either inactive or inaccessible. This meant that over 2.75 million domains from the top 10 million were dead.
| Status Code | Count | Rate |
| ----------- | --------- | ---- |
| 301 | 4,989,491 | 50% |
| 1000 | 1,883,063 | 19% |
| 200 | 1,087,516 | 11% |
| 302 | 659,791 | 7% |
| 0 | 522,221 | 5% |Conclusion
With a dataset as large as 10 million domains, there are bound to be formatting inconsistencies that affect accuracy. For example, domains with a www prefix should ideally be treated the same as those without, yet variations in how URLs are constructed can lead to mismatches. Additionally, some domains serve specific functions, like content delivery networks (CDNs) or API endpoints, which may not have a traditional homepage or may return a 404 status by design. This adds a layer of complexity when interpreting accessibility.
Achieving complete data cleanliness and uniform formatting would require substantial additional processing time. However, with the large volume of data, minor inconsistencies likely constitute around 1% or less of the overall dataset, meaning they don’t significantly affect the final result: more than a quarter of the top 10 million domains are no longer accessible. This suggests that as time passes, your history and contributions on the internet could gradually disappear.
While the scraper itself completes the task in around 10 minutes, the research, development, and testing required to reach this point took days or even weeks of effort.
If this research resonates with you, please consider supporting more work like this by sponsoring me on Patreon. Your support fuels the creation of articles and research projects, helping to keep these insights accessible to everyone. Additionally, if you have questions or projects where you could use consultation, feel free to reach out via email.
The source code for this project is available on GitHub. Please use it responsibly—this is meant for ethical and constructive use, not for overwhelming or abusing servers.
Thank you for reading, and I hope this research inspires a deeper appreciation for the impermanence of the internet.