Support me on Patreon to write more tutorials like this!

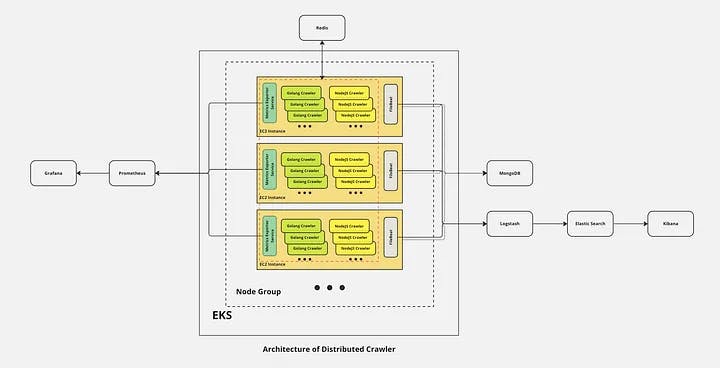
Architecture of Distributed Crawler. Click to see original image.
As part 2 of a series of Distributed Web Crawler articles, if you haven’t read the first part, please check it out here. In the previous article, we mainly focused on the basic concepts and components of a distributed web crawler, as well as the architecture of the entire system. Here, we are going to dive into the coding part, discussing the logic behind the code, why I chose to write the code in this way, and why I selected a particular algorithm to address specific issues.
Since we are dealing with a large-scale distributed system like Google’s crawler, it’s essential to keep efficiency in mind in terms of query time and storage usage. For example, when detecting duplications among billions of URLs, built-in data structures like sets or maps are usually preferred if the dataset is relatively small, say, in the tens of thousands. However, when dealing with billions of items, each around 1 kilobyte in size, thousands of gigabytes of memory would be consumed. This could result in a monthly storage cost of $15,000, not even accounting for other computing expenses. Finding a storage and query-efficient algorithm is crucial in this context. It can save you or your boss a significant amount of money, which can be used as a bargaining chip for a higher salary or position in the future.
Here comes the first and most important data structure we are going to use for de-duplication: Bloom filter
A Bloom filter is a probabilistic data structure used in Redis Stack, which allows you to check whether an element is likely present in a set while using a small, fixed-size memory space.
Rather than storing all elements directly in the set, Bloom Filters store only the hashed representations of elements. This approach sacrifices some precision in exchange for significant space efficiency and fast query times.
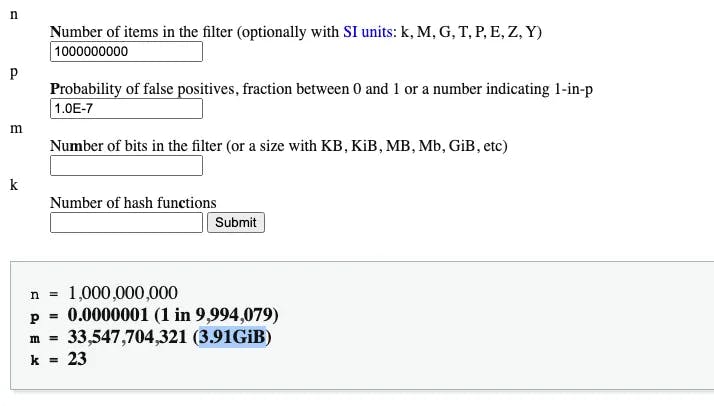
According to the Bloom Filter Calculator, you would need less than 4GB of memory to handle 1 billion items with an error rate as low as 0.0000001.
Most importantly, Redis Stack provides built-in support for Bloom filters. However, if you are using an older version of Redis, you can implement your own Bloom filter in any programming language using another built-in data structure known as bitmaps.
For this project, we have chosen to use redisbloom-go in conjunction with Redis Stack for our Bloom filter algorithm.
package redis
import (
"os"
redisbloom "github.com/RedisBloom/redisbloom-go"
"github.com/tonywangcn/distributed-web-crawler/pkg/log"
)
var rb *redisbloom.Client
func init() {
pass := os.Getenv("REDIS_PASS")
rb = redisbloom.NewClient(os.Getenv("REDIS_HOST")+":"+os.Getenv("REDIS_PORT"), "bloom", &pass)
}
func BloomReserve(key string, error_rate float64, capacity uint64) error {
return rb.Reserve(key, error_rate, capacity)
}
func BloomAdd(key string, item string) (bool, error) {
ok, err := rb.Add(key, item)
if err != nil {
log.Error("failed to add item %s to bloom key %s, err: %s", item, key, err.Error())
return false, err
}
return ok, nil
}Before starting coding, it’s better to use docker compose to manage the local development environment with a single docker-compose.yml file:
version: "3.5"
services:
go:
image: golang:1.20
container_name: go
restart: always
env_file:
- .env
volumes:
- ./go/src:/go/src/github.com/tonywangcn/distributed-web-crawler
working_dir: /go/src/github.com/tonywangcn/distributed-web-crawler
command: [ "tail", "-f", "/dev/null" ]
logging:
driver: "json-file"
options:
max-size: "10m"
max-file: "3"When combined with commands in the makefile, it becomes quite convenient to manage the local environment. You can use make dev to start the container defined in the docker-compose.yml file above and make down to stop the container:
dev:
docker-compose up -d
down:
docker-compose downHere comes the main function of the crawler to scrape data from internet and find new links. There are a few factors we need to take into consideration here.
1): Breadth first search (BFS) or depth first search (DFS) are the two common approaches when traverse a website and find all available links. Here we choose BFS, since we have an efficient algorithm, Bloom filter, to filter out duplicated links, and a dedicated task queue in Redis to distribute tasks between workers. There is no need to revisit any links in this approach.
2). Performance of batch operation in database. All the scraped data will be persisted into MongoDB on disk, compared with memory database like Redis, the speed is quite low. So it’s better to use Redis or Kafka as a message queue to store data for distributed workers to consume and save data into MongoDB in batch later. Though Kafka is more reliable and has a higher throughout than Redis as message queue, because of simplicity of deployment, we choose Redis.
3). Retry. Request may fail anytime in a distributed system, it’s essential to design a retry mechanism to ensure a higher success rate while not overwhelming the system of target website. Here comes a simple version of exponential backoff with Golang builtin function math.Exp. The first time it will sleep for 2.72, the constant Euler’s number, seconds, than 7.39 seconds before the second retry, and 20.09 for the third. Below is the code for it.
c.OnError(func(r *colly.Response, err error) {
retriesLeft := CRAWLER_MAX_RETRIES
if x, ok := r.Ctx.GetAny("retriesLeft").(int64); ok {
retriesLeft = x
}
log.Error("error %s | retriesLeft %d", err.Error(), retriesLeft)
if retriesLeft > 0 {
r.Ctx.Put("retriesLeft", retriesLeft-1)
time.Sleep(time.Duration(math.Exp(float64(CRAWLER_MAX_RETRIES-retriesLeft+1))) * time.Second)
r.Request.Retry()
}
})4). Statistical information. As the distributed system is running, we might need to monitor it in realtime, like how many urls are processed under that domain name, and how many external urls are found in a website. If a website has more external backlinks from popular website like BBC, it usually means a higher priority in the Google Search results. Thus we should prioritize the scraping task of that website. Here we rely on Hash data structure in Redis to store the counter with a command like HINCRBY key field increment which is perfect fit for such scenario. With command HGETALL key you can see the statistical result like below after some time running:
{b'account.bbc.com': b'360', b'canvas-story.bbcrewind.co.uk': b'1', b'downloads.bbc.co.uk': b'56', b'www.bbc.com': b'151'}// the main function of scraping.
func scrape() {
// recieve task from redis queue
u := redis.LPop(GO_CRAWLER_TASK_QUEUE)
if len(u) == 0 {
log.Error("invalid url %s", u)
return
}
// parse hostname from url
var hostname = utils.GetHostname(u)
// check hostname if valid
if !utils.IsValidHostname(hostname) {
log.Error("illegal url %s, hostname %s", u, hostname)
return
}
// read robots.txt file and check url is allowed
robo := robots.New("http://" + hostname)
if !robo.AgentAllowed("GoogleBot", u) {
log.Error("URL is not allowed to visit in robots.txt. URL: %s", u)
return
}
var c = colly.NewCollector(
colly.UserAgent(os.Getenv("GO_BOT_UA")),
colly.AllowURLRevisit(),
)
c.Limit(&colly.LimitRule{
RandomDelay: 2 * time.Second,
})
// create the redis storage
storage := &redisstorage.Storage{
Address: os.Getenv("REDIS_HOST") + ":" + os.Getenv("REDIS_PORT"),
Password: os.Getenv("REDIS_PASS"),
DB: 0,
Prefix: "crawler:" + hostname,
}
// add storage to the collector
err = c.SetStorage(storage)
if err != nil {
log.Error(err.Error())
panic(err)
}
// close redis client
defer storage.Client.Close()
// create a new request queue with redis storage backend
q, _ := queue.New(50, storage)
// Process any errors caused by timeout, status code >= 400
c.OnError(func(r *colly.Response, err error) {
retriesLeft := CRAWLER_MAX_RETRIES
if x, ok := r.Ctx.GetAny("retriesLeft").(int64); ok {
retriesLeft = x
}
log.Error("error %s | retriesLeft %d", err.Error(), retriesLeft)
if retriesLeft > 0 {
r.Ctx.Put("retriesLeft", retriesLeft-1)
time.Sleep(time.Duration(math.Exp(float64(CRAWLER_MAX_RETRIES-retriesLeft+1))) * time.Second)
r.Request.Retry()
}
})
c.OnResponse(func(r *colly.Response) {
if err = redis.HIncryBy(GO_CRAWLER_REQUEST_HOSTNAME_STATS, hostname, 1); err != nil {
log.Error(err.Error())
}
content := parse(r)
content.Domain = hostname
content.URL = r.Request.URL.String()
b, err := json.Marshal(content)
if err != nil {
log.Error("failed to marshal struct to json, url: %s", content.URL)
return
}
if err := redis.LPush(GO_CRAWLER_RESULT_QUEUE, b); err != nil {
log.Error(err.Error())
}
})
c.OnHTML("a", func(e *colly.HTMLElement) {
// get the url of the element
link := e.Request.AbsoluteURL(e.Attr("href"))
if len(link) == 0 {
return
}
// read robots.txt file and check url is allowed
if !robo.AgentAllowed("GoogleBot", link) {
log.Error("URL is not allowed to visit in robots.txt. URL: %s", link)
return
}
u, err := url.ParseRequestURI(link)
if err != nil {
log.Error("illegal url %s, err:%s", link, err.Error())
return
}
if !utils.IsValidHostname(u.Hostname()) {
log.Error("illegal url %s, hostname %s", link, u.Hostname())
return
}
if !utils.IsValidPath(u.Path) {
log.Error("illegal path %s, hostname %s", u.Path, u.Hostname())
return
}
link = utils.CleanUpUrlParam(u)
ok, err := redis.BloomAdd(CRAWLER_BLOOM_KEY, crypto.Md5(strings.Replace(strings.TrimSuffix(link, "/"), "http://", "https://", 1)))
if err != nil {
log.Error(err.Error())
return
}
if !ok {
log.Debug("URL has been crawled already, %s", u)
return
}
log.Info("Found new Url %s", u)
// prioritize links in the same domain
if u.Hostname() == hostname {
q.AddURL(link)
} else {
if err = redis.LPush(OUT_LINK_QUEUE, link); err != nil {
log.Error(err.Error())
}
if err := redis.HIncryBy(OUT_LINK_HOST_COUNTER, u.Hostname(), 1); err != nil {
log.Error(err.Error())
}
}
})
c.OnRequest(func(r *colly.Request) {
log.Info("Visiting %s", r.URL.String())
})
// add URLs to the queue
q.AddURL(u)
// consume requests
q.Run(c)
}Conclusion
In this series of articles, we’ve delved into the intricacies of building a distributed web crawler, from conceptual foundations to the practical implementation details. We’ve explored key components and made critical decisions to ensure efficiency and reliability in the face of vast amounts of data.
-
We discussed the choice of using Breadth-First Search (BFS) as our traversal algorithm, leveraging the power of a Bloom filter to eliminate duplicate links and a dedicated Redis task queue for efficient task distribution.
-
Recognizing the importance of performance in database operations, we opted to persist scraped data into MongoDB while using Redis or Kafka as a message queue to facilitate distributed processing. Our choice was influenced by the simplicity of Redis deployment.
-
To enhance robustness, we implemented a retry mechanism using a simple version of
exponential backoffwith Golang’s built-inmath.Expfunction. This mechanism helps ensure a higher success rate while avoiding overwhelming target websites. -
Additionally, we explored the significance of statistical information in real-time monitoring. Utilizing Redis’s Hash data structure, we stored counters to track various metrics such as the number of processed URLs under a specific domain and the count of external URLs. This data enables us to make informed decisions, such as prioritizing the scraping of websites with more external backlinks.
By combining these strategies and leveraging Redis Stack and other technologies, we’ve successfully developed the core code of our distributed web crawler. If you’re interested in diving deeper and exploring the source code, please check out the GitHub repository.
Stay tuned for more articles in this series, where we’ll continue to explore advanced topics and best practices in building powerful distributed web scraping systems. Subscribe and follow for updates to embark on this exciting journey of web crawling mastery. Happy crawling!