Support me on Patreon to write more tutorials like this!

There’ve been lots of articles about how to build a python crawler . If you are a newbie in python and not familiar with multiprocessing or multithreading , perhaps this tutorial will be right choice for you.
You don’t need to know how to manage processing or thread or even queue, just input the urls you want to scrape, extract the web structure as you need , change the number of crawlers and concurrencies to generate, and the rest of all is “Fire it up”!
All the code here just simulate an efficient distributed crawler, and learn how to use docker and celery . There are a few things to declare before we get started:
-
No matter which website you want to scrape, please obtain its robot policy and TOS.
-
Don’t send large requests to the same website at one time. Please be gentle.
-
Don’t do anything that violate local law of you country
This tutorial is a upgrade version of previous post, How to build docker cluster with celery and RabbitMQ in 10 minutes. There are lots of technical details about how to write a dockerfile , use docker-compose, and how to configure Celery and RabbiMQ , so I won’t talk about them again.
1.Let’s Go
Because of Docker, we could scale up any applications easily. So there are only two key files in this article. Check the previous post for more details.
KEY ONE
from .tasks import longtime_add
import time
if __name__ == '__main__':
url = ['http://example1.com', 'http://example2.com', 'http://example3.com', 'http://example4.com'] # change them to your ur list.
for i in url:
result = longtime_add.delay(i)
print 'Task result:', result.resultList of urls: you could get a Alexa top 1 million domain list from this website, store them into your database or text file as your need. In order to have a quick test , I just build a nginx hello page in my cloud server. Then scale it up to a list of 1000000.
Then use longtime_add.delay method to send all of them to RabbitMQ, a message broker.
KEY TWO
from __future__ import absolute_import
from test_celery.celeryapp import app
import time
import requests
from pymongo import MongoClient
client = MongoClient('10.211.55.12', 27018) # change the ip and port to your mongo database's
db = client.mongodb_test
collection = db.celery_test
post = db.test
@app.task(bind=True, default_retry_delay=10) # set a retry delay, 10 equal to 10s
def longtime_add(self, i):
print 'long time task begins'
try:
r = requests.get(i)
post.insert({'status': r.status_code,"creat_time": time.time()}) # store status code and current time to mongodb
print 'long time task finished'
except Exception as exc:
raise self.retry(exc=exc)
return r.status_code
With a command of docker-compose scale worker=10, docker-compose will generate a worker cluster with this tasks file. It will get a list of urls and send it to requests, return the status_code , and store status_code with time.time() method. If it works , you will see something like this in Mongo database:
{‘status’:200,’create_time’:1488271604.63484}Generally,because of the network of your home or server host , connections are not always stable, once it fails we have to try again. So we set a retry delay to 10 seconds here. Once failling it will retry 10 second later.
@app.task(bind=True,default_retry_delay=10)2.Configure dockerfile and docker-compose
ENTRYPOINT celery -A test_celery worker — concurrency=20 — loglevel=infoSomething should be noticed here: do not set the concurrency in dockerfile too high. In this case, 20 is big enough for my machine.
What we should add in docker-compose file is mongo database, and set the port 27018:27017 . The first number should be the same as the one in tasks.
3. Let’s Run
If you find it’s a little difficult to follow up, just clone the code to your local machine, then do the same thing as previous article.
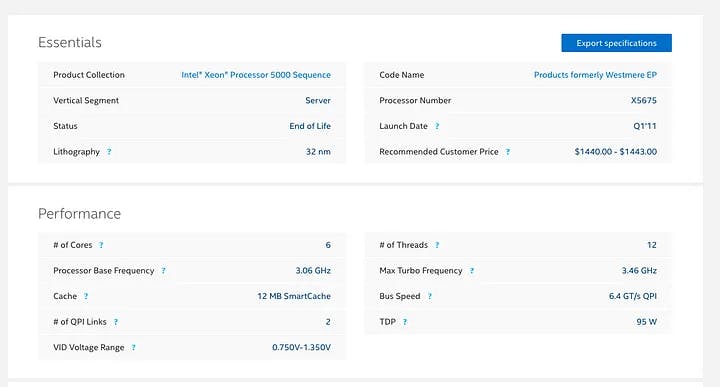
My local machine has two CPUs , while each one has 12 threads and 6 cores, and total memory is 32G . It’s powerful enough to run 40 workers while each one has 20 concurrencies.
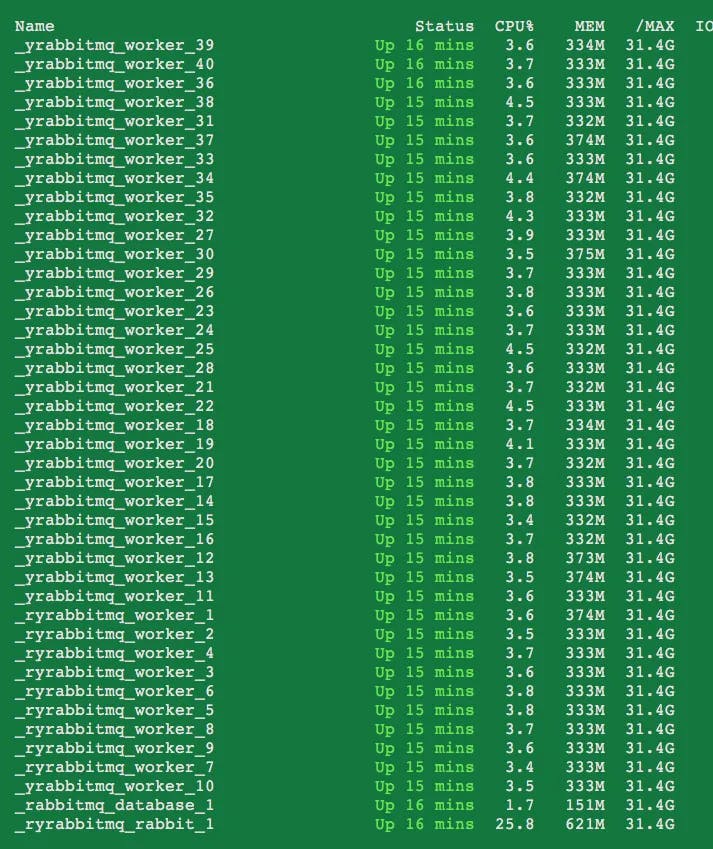
The more concurrencies for each worker, the more memory it will need. For this case , the 40 workers cost about 12G memory totally, and about a half left. If I increase the number of concurrencies or workers a little bit, the speed of crawler will be faster, however the bandwidth of network in my house is just 1 mb/s. Though increasing of workers, the speed doesn’t increase at all. In this test , the bottleneck is my poor network.
40 workers and 15 minutes later, I got about 100000 items in my Mongo database, using a single machine.
Conclusion
If you have a powerful server or pc, it's necessary to deploy docker clusters to maximize performance of your machine, or with some small server such as Raspberry Pi , docker is a better choice too. Of course , without docker you could build a distributed crawler too. Some software like Fabric will deploy your applications to server clusters with few commands.
If you have any questions or suggestions about it , please feel free to drop response here , and welcome to submit pull requests to this project. See you next tutorial!