Support me on Patreon to write more tutorials like this!

Handling a massive volume of requests on a tight budget is one of the most challenging goals in cloud computing today. In this article, we'll break down the infrastructure required to achieve a target of 10 million requests in 10 minutes, all for around $0.0116. This guide goes beyond basic setup and explores practical considerations for production-ready systems, balancing cost efficiency and high availability.
Key Takeaways: This guide is perfect for those looking to set up a high-volume infrastructure on a budget. You’ll learn how to use Golang, Kubernetes, Redis, and Terraform to create a scalable, reliable system. Whether you're scaling an API for heavy traffic, handling data-intensive tasks, or exploring distributed systems, this setup provides a foundation for success.
This article builds on the infrastructure concepts from our previous post, 27.6% of the Top 10 Million Sites are Dead. We encourage you to review that article to understand the broader importance of robust infrastructure, especially when handling high volumes of web traffic and data processing.
Why This Setup?
Some might argue that achieving this with minimal cost is overengineering. While it's true that a one-off project could leverage simple parallelization or even curl, that approach falls short when creating a reusable, scalable product with monitoring, task management, and fault tolerance. This setup provides a great learning path if you're new to distributed systems and infrastructure and are looking to build a solid foundation for scaling web services.
Requirements: Familiarity with Terraform and Kubernetes is helpful but not required, as we'll walk through key steps.
Cost Analysis: Why Rackspace Spot?
Before diving into infrastructure specifics, let's explore the cost differences between AWS, Hetzner, and Rackspace Spot. It's important to note that the AWS and Rackspace Spot pricing is based on spot instances. These instances operate in an auction market where demand can drive prices up, and previously bid instances may be reclaimed as demand increases. Conversely, Hetzner's offering is more akin to on-demand instances that you can keep for as long as needed, without worrying about unexpected terminations.
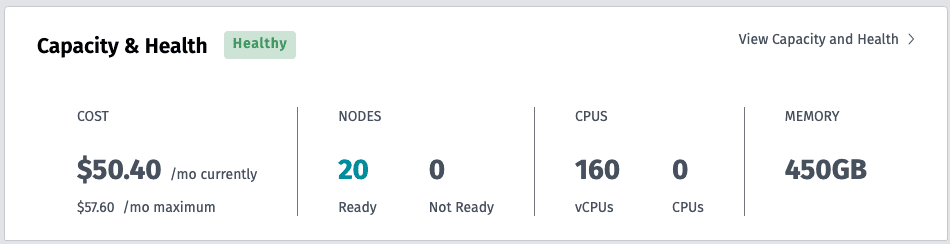
It's evident that Hetzner offers a significant cost advantage, with rates approximately 3 times lower than AWS, but around 7 times higher than Rackspace Spot. While Hetzner does offer even cheaper auction-based servers, they aren't included here as they lack API integration for Terraform and Kubernetes, making cluster management less streamlined.
| Provider | Instance Type | Hourly Rate (USD) | Pricing Context | Pricing Reference |
|---|---|---|---|---|
| AWS | c6g.xlarge | $0.0428 | Linux Spot Minimum Cost | AWS Pricing |
| Hetzner | CX32 | $0.0141 | Standard Pricing | Hetzner Cloud Pricing |
| Rackspace Spot | ch.vs1.large-dff | $0.002 | 80th Percentile Pricing | Rackspace Spot Pricing |
To illustrate, 20 Hetzner instances with 160 vCPUs and 450GB of memory are still cheaper than running two AWS Spot c6g.xlarge instances. This low price point makes maintaining a Kubernetes cluster feasible and more affordable for a wider audience. However, since Rackspace Spot is auction-based, it may not suit users unfamiliar with Kubernetes, as instances aren't directly accessible through SSH via public IPs.
Infrastructure Setup
Step 1: Requirements
- Terraform for infrastructure as code
- Kubectl for Kubernetes management
- Helm for managing Kubernetes applications
- Rackspace Spot Account to access spot instances
Additionally, git is required to clone the project repository: https://github.com/tonywangcn/ten-million-domains.
In your Rackspace Spot account, go to API Access, create a token, and save it in a terraform.tfvars file within the terraform folder as shown below:
rackspace_spot_token = "YOUR_RACKSPACE_SPOT_TOKEN"Step 2: Create the cluster with Terraform
- Configuring the Kubernetes Cluster with Terraform
All Terraform files are located in the terraform folder. Here's a snippet from main.tf:
variable "region" {
description = "Region for the Spot instance"
type = string
default = "us-east-iad-1"
}
resource "spot_spotnodepool" "gp-1" {
cloudspace_name = spot_cloudspace.cluster.cloudspace_name
server_class = "gp.vs1.2xlarge-${local.region_suffix}"
bid_price = 0.005
desired_server_count = 10
}
# Output kubeconfig to local file
resource "local_file" "kubeconfig" {
filename = "${path.module}/kubeconfig-${spot_cloudspace.cluster.cloudspace_name}.yaml" # Path to the file with the cluster name
content = data.spot_kubeconfig.cluster.raw # The kubeconfig content
}- Region: Update the region variable to one that offers competitive pricing, such as
us-east-iad-1. - Bid Price: Each
spot_spotnodepoolresource sets a bid price per instance type, based on availability and 80th percentile cost (use CloudPricing for reference).
- Running Terraform Commands
With everything set up, initialize, validate, plan, and apply the configuration with make tf:
tf:
- terraform -chdir=./terraform init --upgrade
terraform -chdir=./terraform validate
terraform -chdir=./terraform plan
terraform -chdir=./terraform apply -auto-approveExpect the setup to take 20–30 minutes. You can monitor progress in the Rackspace Spot console.
Step 3: Redis Cluster and worker cluster
Since the cluster uses spot instances, any instance can be terminated if outbid. For high availability, we deploy a Redis cluster with Sentinel using the Bitnami Redis Helm chart. Configure the password before deployment. Here's an example values.yaml:
architecture: replication
auth:
enabled: true
password: "YourSecurePassword"
replica:
resources:
requests:
cpu: "500m"
memory: "1Gi"
limits:
cpu: "3"
memory: "8Gi"
replicaCount: 3
disableCommands: []
sentinel:
enabled: true
redisShutdownWaitFailover: true
resources:
requests:
cpu: "500m"
memory: "1Gi"
limits:
cpu: "3"
memory: "8Gi"Run make redis to deploy the Redis cluster with Sentinel.
redis: helm
helm upgrade --install redis-cluster bitnami/redis -f ./helm/redis/values.yaml --namespace redis --create-namespace
helm:
helm repo add bitnami https://charts.bitnami.com/bitnami
Step 4: Worker Cluster Deployment
Before deploying worker clusters, create a Docker registry secret for deployment. Set up a .env file with your GitHub username and personal access token, then run:
secret:
kubectl create secret docker-registry github-registry-secret \
--docker-server=ghcr.io \
--docker-username=${GITHUB_USERNAME} \
--docker-password=${GITHUB_PERSONAL_ACCESS_TOKEN} \
-o yaml > k8s/secret.yamlFinally, deploy the worker clusters:
d:
kubectl delete -f ./k8s/job.yaml --ignore-not-found
kubectl apply -f ./k8s
Step 5: Exposing Services via Cloudflare Tunnel
For workloads on spot instances without a static public IP, accessing services deployed within the cluster using a domain name can be challenging. A common solution is to create a load balancer to expose internal services to the internet, typically costing around $10 per month. However, a more cost-effective and secure approach is to use Cloudflare Tunnel. This service acts as a secure conduit, enabling access to your server while keeping it hidden from direct exposure to the internet.
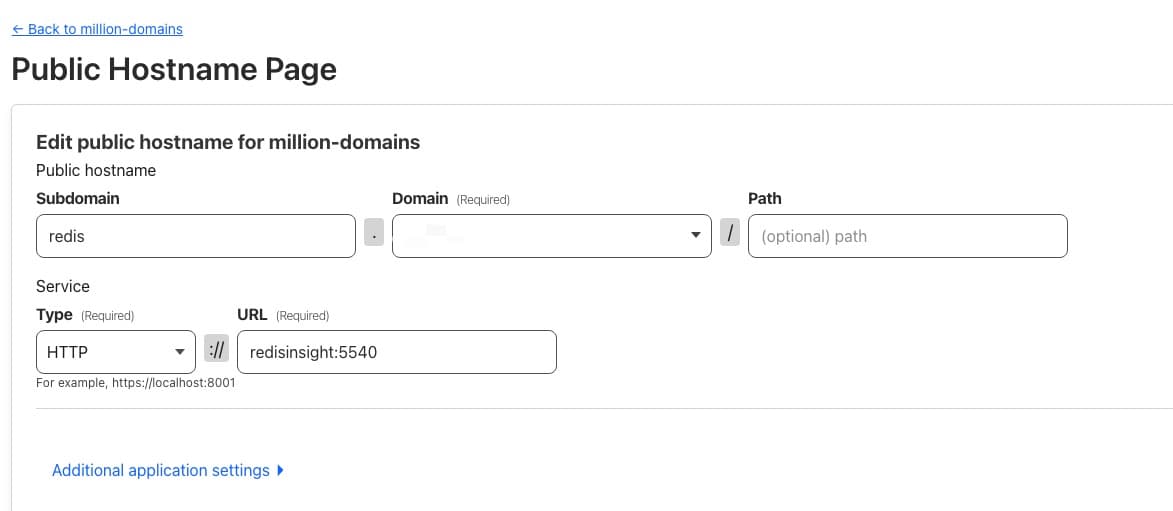
The deployment file below demonstrates how to set up a Cloudflare Tunnel to expose the redis-insight service, which we deployed previously. With this configuration, you can access the Redis Insight Web UI at a domain like redis.yourdomainname.com by configuring the hostname settings on Cloudflare Tunnel, as shown in the image below.
apiVersion: apps/v1
kind: Deployment
metadata:
name: cloudflared
spec:
selector:
matchLabels:
app: cloudflared
replicas: 1
template:
metadata:
labels:
app: cloudflared
spec:
containers:
- name: cloudflared
image: cloudflare/cloudflared:2024.9.1
resources:
requests:
cpu: 200m
memory: 256Mi
limits:
cpu: 1000m
memory: 1024Mi
args:
- tunnel
- --config
- /etc/cloudflared/config/config.yaml
- --loglevel
- debug # Enable debug logging
- run
- --token
- <cloudflare-tunnel-token-replace-me-please>
- --protocol
- http2
livenessProbe:
httpGet:
# Cloudflared has a /ready endpoint which returns 200 if and only if
# it has an active connection to the edge.
path: /ready
port: 2000
failureThreshold: 1
initialDelaySeconds: 10
periodSeconds: 10
volumeMounts:
- name: config
mountPath: /etc/cloudflared/config
readOnly: true
volumes:
# Create a config.yaml file from the ConfigMap below.
- name: config
configMap:
name: cloudflared-cfg
items:
- key: config.yaml
path: config.yaml
---
apiVersion: v1
kind: ConfigMap
metadata:
name: cloudflared-cfg
data:
config.yaml: |
tunnel: million-domains
metrics: 0.0.0.0:2000
no-autoupdate: true
Conclusion
Rackspace Spot is a relatively new service developed by a team from Rackspace, a publicly traded company on NASDAQ with a long history in the cloud computing industry. There are, however, several known issues, some of which might have already been fixed, such as network performance between nodes, rollbacks of changes to default components like CoreDNS due to its Kubernetes controller-based design, and a 500 error when generating a new access token. Despite these issues, Rackspace Spot can be a good choice for developers working on hobby or research projects. However, it's essential to validate it thoroughly before using it in production, as there may be additional, unforeseen issues.
As mentioned in the previous post, CPU usage is around 30%. The number of servers deployed for this project exceeds current needs, so optimizing resource allocation could reduce costs and improve performance further.